
Python Web Scraping Documentation
In this post, you will learn about the Python web scraping documentation.
Web Scraping is a process of data extracting from web sites. The extracted data can be content, urls, contact information, etc, which we can store in a local file or database. This process can be done manually by code called scrapper or by an automated software implemented using a bot or web crawler. The web scraping is not always legal. Some sites have dis-allow the scraping in the 'robots.txt' file. Some popular sites provide APIs to access their data in a structured way. But not all websites. So, we need a web scraper for data extraction, data mining and storing in a structured way.
Python is the most popular programming language for web scraping. It provides many libraries that can handle web crawler related process smoothly. Scrapy and BeautifulSoup are among the widely used libraries.
Python Web Scraping Library
In this article, we have used the Requests and BeautifulSoup modules to develop web scraping in Python.
Install requests module
The requests module makes a HTTP request to the specified web page using Python and returns a response object. This module is used with the Python web scraping module. The installation process of this package is similar to the other Python packages. We can either download this from GitHub or install it using pip tool.
$ pip install requestsMake a GET request
The GET method returns data of the requested url. Suppose we want to fetch the HTML page content of a job search portal using requests get method.
import requests
URL = 'https://www.monster.com/jobs/search/?q=Clinical-Data-Analyst&where=California'
page = requests.get(URL)
print(page.text)
print(page.status_code)The above code returns the requested page and status code.
Beautifulsoup module
The beautifulsoup library makes it easy to scrape the information from the HTML or XML files. The Beautiful Soup4 or bs4 works on Python 3. It is much faster and supports third party parsers like html5lib and lxml. The following command installs the BeautifulSoup module using pip tool.
pip install bs4On successful installation, it returns the following -
Successfully built bs4
Installing collected packages: soupsieve, beautifulsoup4, bs4
Successfully installed beautifulsoup4-4.8.2 bs4-0.0.1 soupsieve-2.0For web scraping, first we need to import this module and pass the fetched url content to create soup object. This library provides find_all method to filter data from the web content.
Python Web Scraping Examples
Suppose, we want to get all the title of 'h2' tags from the request url, the code will be -
import requests
from bs4 import BeautifulSoup
URL = 'https://www.monster.com/jobs/search/?q=Clinical-Data-Analyst&where=California'
page = requests.get(URL)
soup = BeautifulSoup(page.content, 'html.parser')
x = soup.find_all('h2', class_='title')
for job_title in x:
print(job_title.text.strip())
The above code returns the following output -
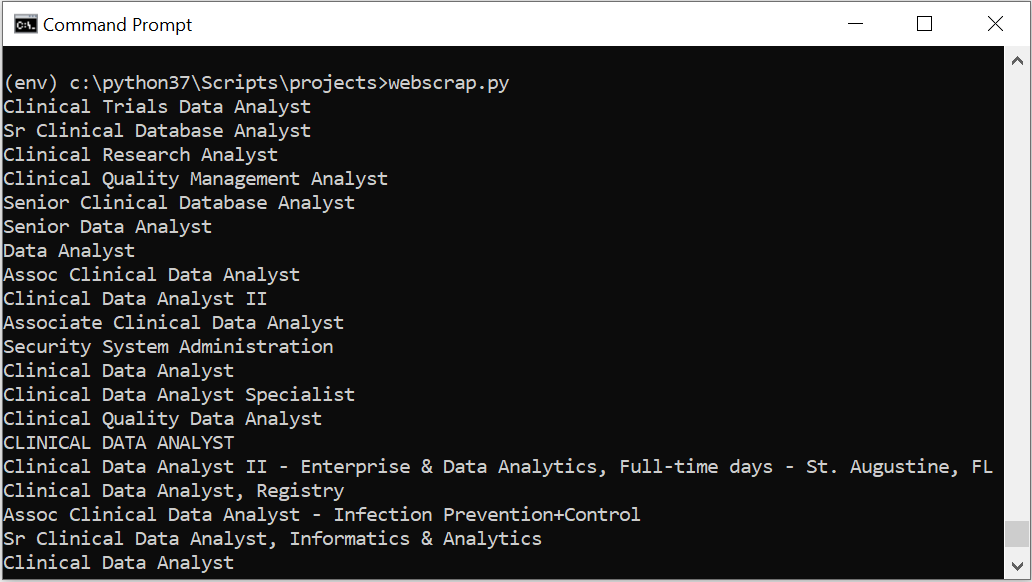
Similarly, if we want to get all the hyperlinks within the 'h2' tag, the code will be -
import requests
from bs4 import BeautifulSoup
URL = 'https://www.monster.com/jobs/search/?q=Clinical-Data-Analyst&where=California'
page = requests.get(URL)
soup = BeautifulSoup(page.content, 'html.parser')
x = soup.find_all('h2', class_='title')
for job_title in x:
link = job_title.find('a')['href']
print(link)The above code returns the following output -
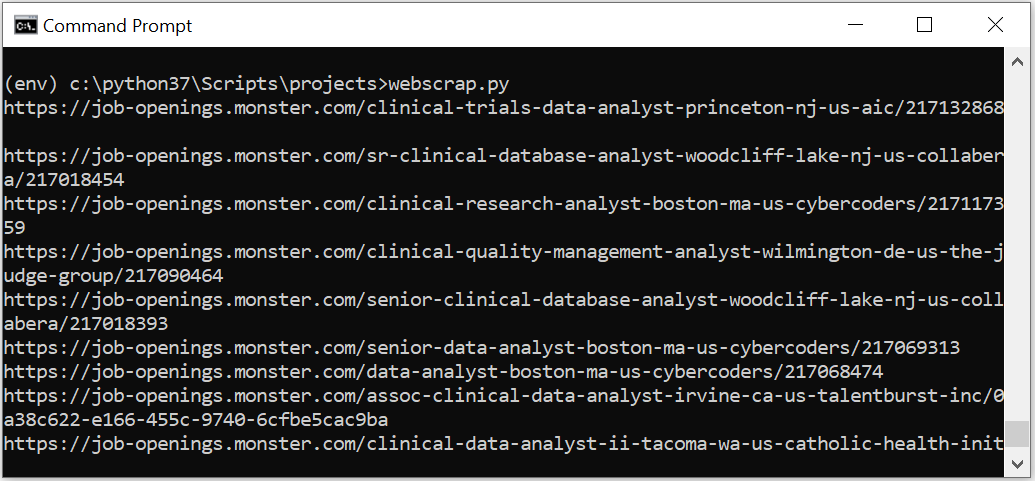
Related Articles
Python Read XML File Line By LineHow to insert JSON data into MongoDB using Python
How to display mongodb data in HTML page
CRUD operations in Python using MongoDB connector
Write Python Pandas Dataframe to CSV
Quick Introduction to Python Pandas
Python Pandas DataFrame
Python3 Tkinter Messagebox
Python get visitor information by IP address
Python Webbrowser
Python Tkinter Overview and Examples
Python Turtle Graphics Overview
Factorial Program in Python
Python snake game code with Pygame
Python JSON Tutorial - Create, Read, Parse JSON file
Python convert xml to dict
Python convert dict to xml



